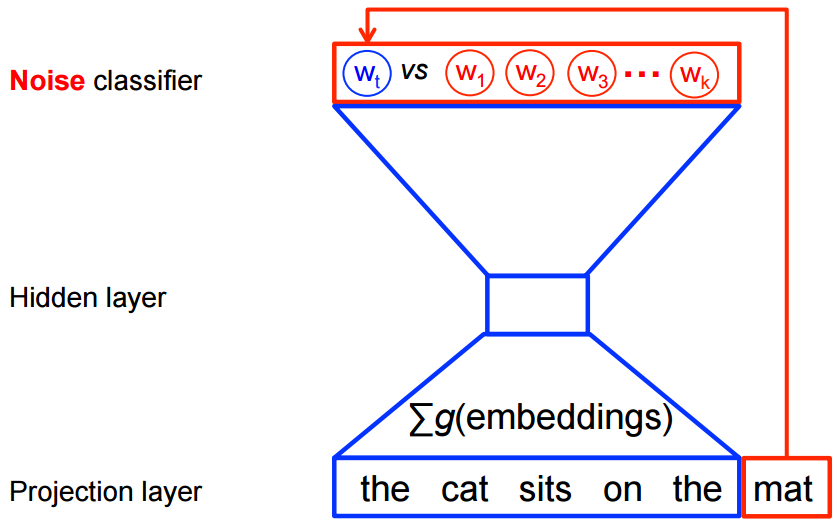
Neural probabilistic language models are traditionally trained using the maximum likelihood principle to estimate the probability distribution of the next word $w_t \in Vocabulary$ ($t$ for "targets") given the previous words $h$ ($h$ for "history") in terms of a softmax function. In other words, we build a multi-label classification model whose classes include all the words in the vocabulary.
Scenario of traditional laguage model task:

Note that the network outputs the entire distribution for all words in the vocabulary set, not only the most likely word (the red "here" in the image).
The classic neural language model (Bengio et al., 2001; 2003) contains three layers:
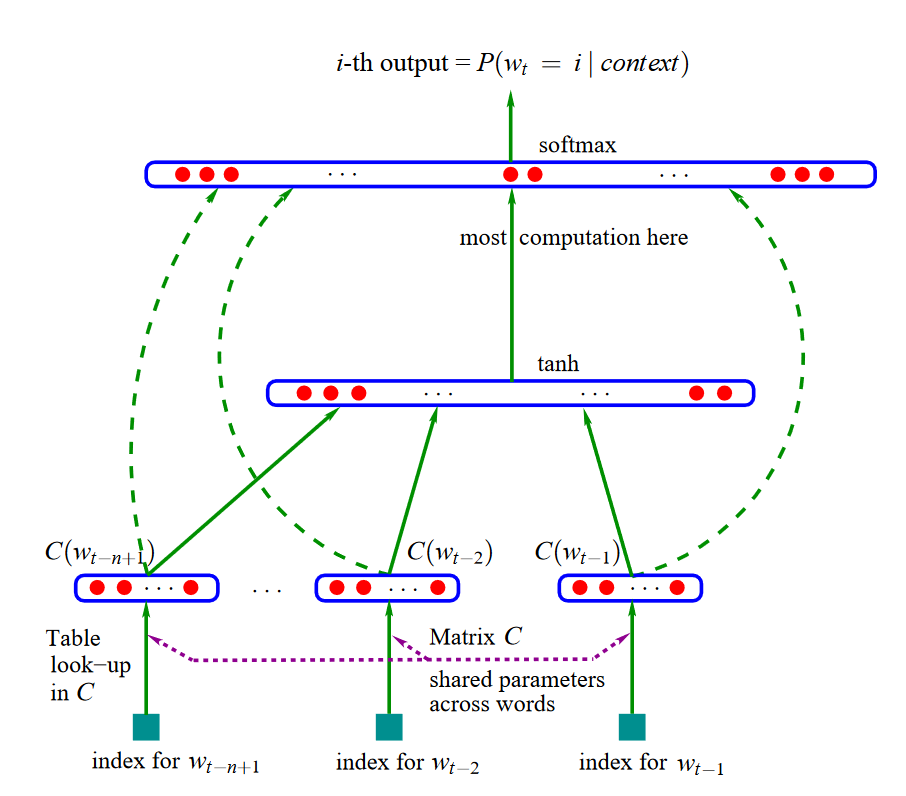
- Embedding Layer: a layer that generates word embeddings by multiplying an index vector with a word embedding matrix.The layer can be understood as a lookup table that maps from integer indices (which stand for specific words) to dense vectors (their embeddings);
- Intermediate Layer(s): one or more layers that concatenate inputs and produce an intermediate representation, e.g. a fully-connected layer that applies a non-linearity to the concatenation of word embeddings of n previous words;
- Softmax Layer: the final layer that produces a probability distribution over words in $V$.
The probability distribution of the next words $w_t \in Vocab$
$$P(w_t|h)=\textrm{softmax}(\textrm{score}(w_t,h))=\frac{\textrm{exp}\{\textrm{score}(w_t,h)\}}{\sum_{\textrm{Word w in Vocab}}\textrm{exp}\{\textrm{score}(w,h)\}}$$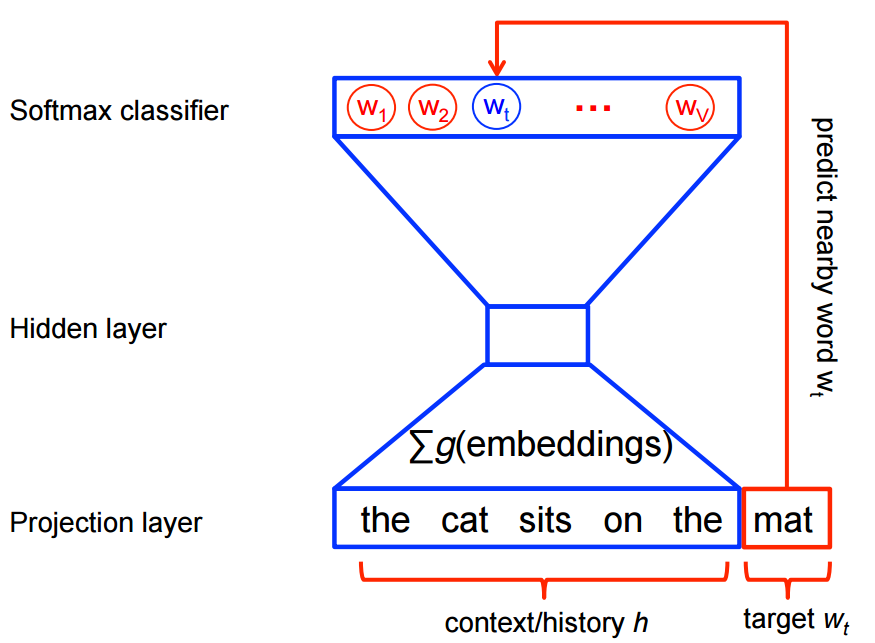
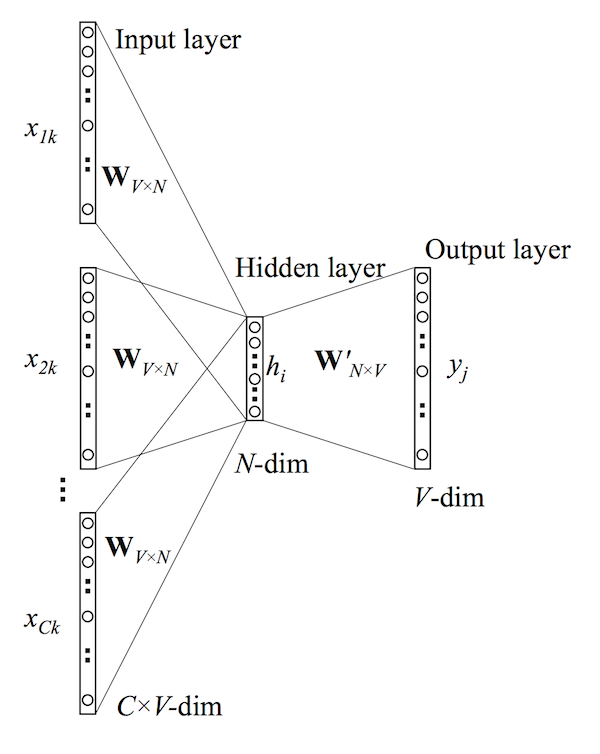
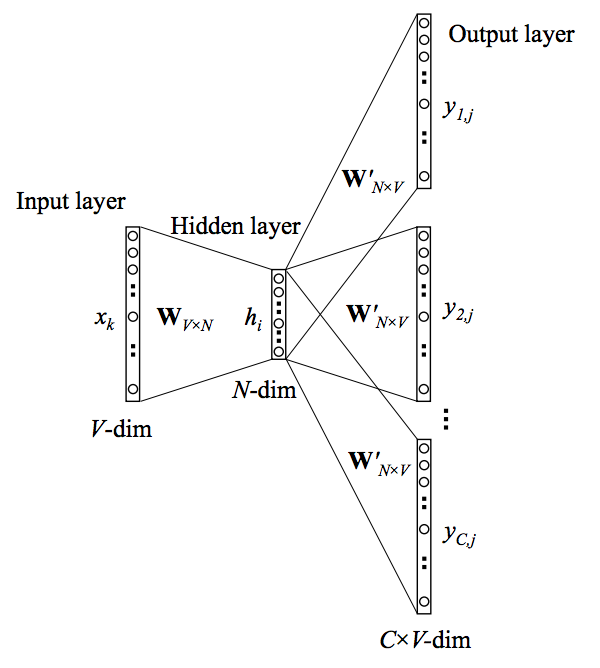
 </center
</center

