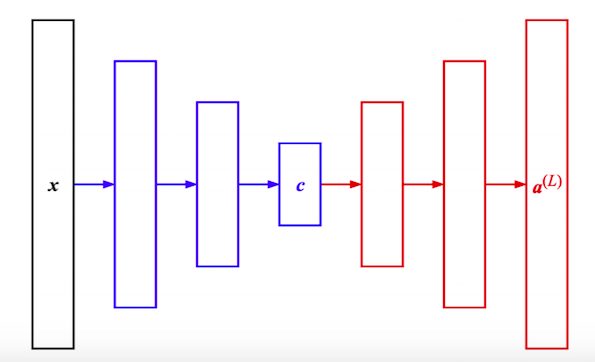
rng = np.random.RandomState(RNG_SEED)
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(-1, 28, 28, 1).astype('float32')
test_images = test_images.reshape(-1, 28, 28, 1).astype('float32')
# Normalizing the images to the range of [0., 1.]
train_images /= 255.0
test_images /= 255.0
x_train = train_images[VALID_SIZE : ]
x_valid = train_images[: VALID_SIZE]
x_test = test_images[: TEST_SIZE]
TRAIN_SIZE = len(x_train)
TRAIN_RCP = np.float32(1.0 / TRAIN_SIZE)
VALID_RCP = np.float32(1.0 / VALID_SIZE)
x_train_noise = np.clip(
x_train + rng.normal(loc = 0.0, scale = NOISE, size = (TRAIN_SIZE, MNIST_H, MNIST_W, MNIST_C)).astype(np.float32),
0.0,
1.0
)
x_valid_noise = np.clip(
x_valid + rng.normal(loc = 0.0, scale = NOISE, size = (VALID_SIZE, MNIST_H, MNIST_W, MNIST_C)).astype(np.float32),
0.0,
1.0
)
x_test_noise = np.clip(
x_test + rng.normal(loc = 0.0, scale = NOISE, size = (TEST_SIZE, MNIST_H, MNIST_W, MNIST_C)).astype(np.float32),
0.0,
1.0
)
# build datasets
ds_train = tf.data.Dataset.from_tensor_slices(x_train).batch(BATCH_SIZE)
ds_valid = tf.data.Dataset.from_tensor_slices(x_valid).batch(BATCH_SIZE)
ds_train_noise = tf.data.Dataset.from_tensor_slices(x_train_noise).batch(BATCH_SIZE)
ds_valid_noise = tf.data.Dataset.from_tensor_slices(x_valid_noise).batch(BATCH_SIZE)
# show data
dmy = []
print('origin data')
fig, axs = plt.subplots(1, 10, figsize=(10,1))
for idx, ax in enumerate(axs):
ax.imshow(x_train[idx][:, :, 0], cmap = 'gray')
ax.set_xticks(dmy)
ax.set_yticks(dmy)
plt.show()
print('noisy data')
fig, axs = plt.subplots(1, 10, figsize=(10,1))
for idx, ax in enumerate(axs):
ax.imshow(x_train_noise[idx][:, :, 0], cmap = 'gray')
ax.set_xticks(dmy)
ax.set_yticks(dmy)
plt.show()