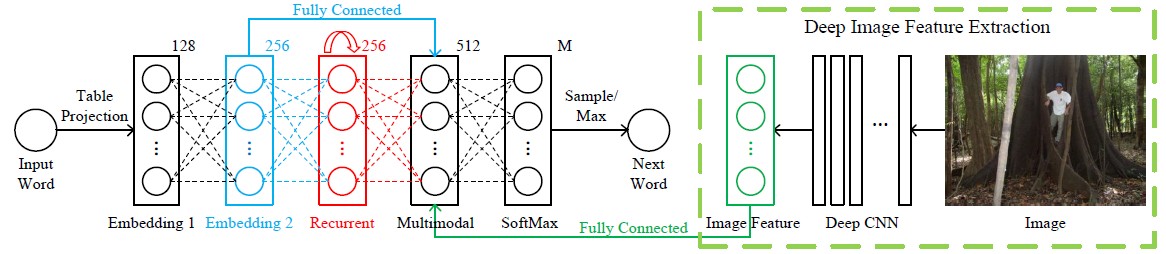
This paper presents a multimodal Recurrent Neural Network (m-RNN) model for generating novel sentence descriptions to explain the content of images.
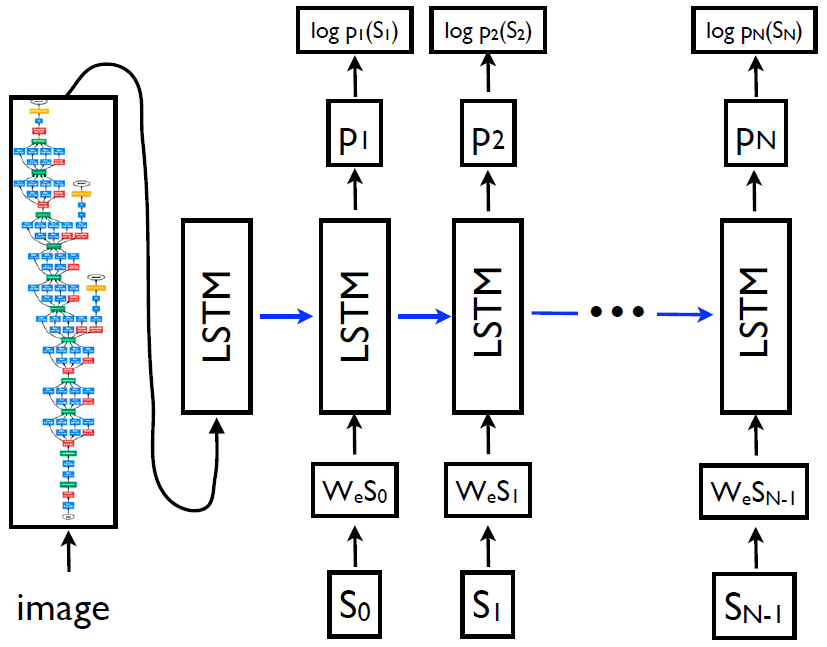
To the best of our knowledge, this is the first work that incorporates the Recurrent Neural Network in a deep multimodal architecture.
The whole m-RNN architecture contains 3 parts: a language model part, an image part and a multimodal part.
- The language model part learns the dense feature embedding for each word in the dictionary and stores the semantic temporal context in recurrent layers.
- The image part contains a deep Convolutional Neural Network (CNN) which extracts image features.
- The multimodal part connects the language model and the deep CNN together by a one-layer representation.
It must be emphasized that:
- The image part is AlexNet, which connects the seventh layer of AlexNet to the multimodal layer.
- This model feeds the image at each time step.








{kind=link}